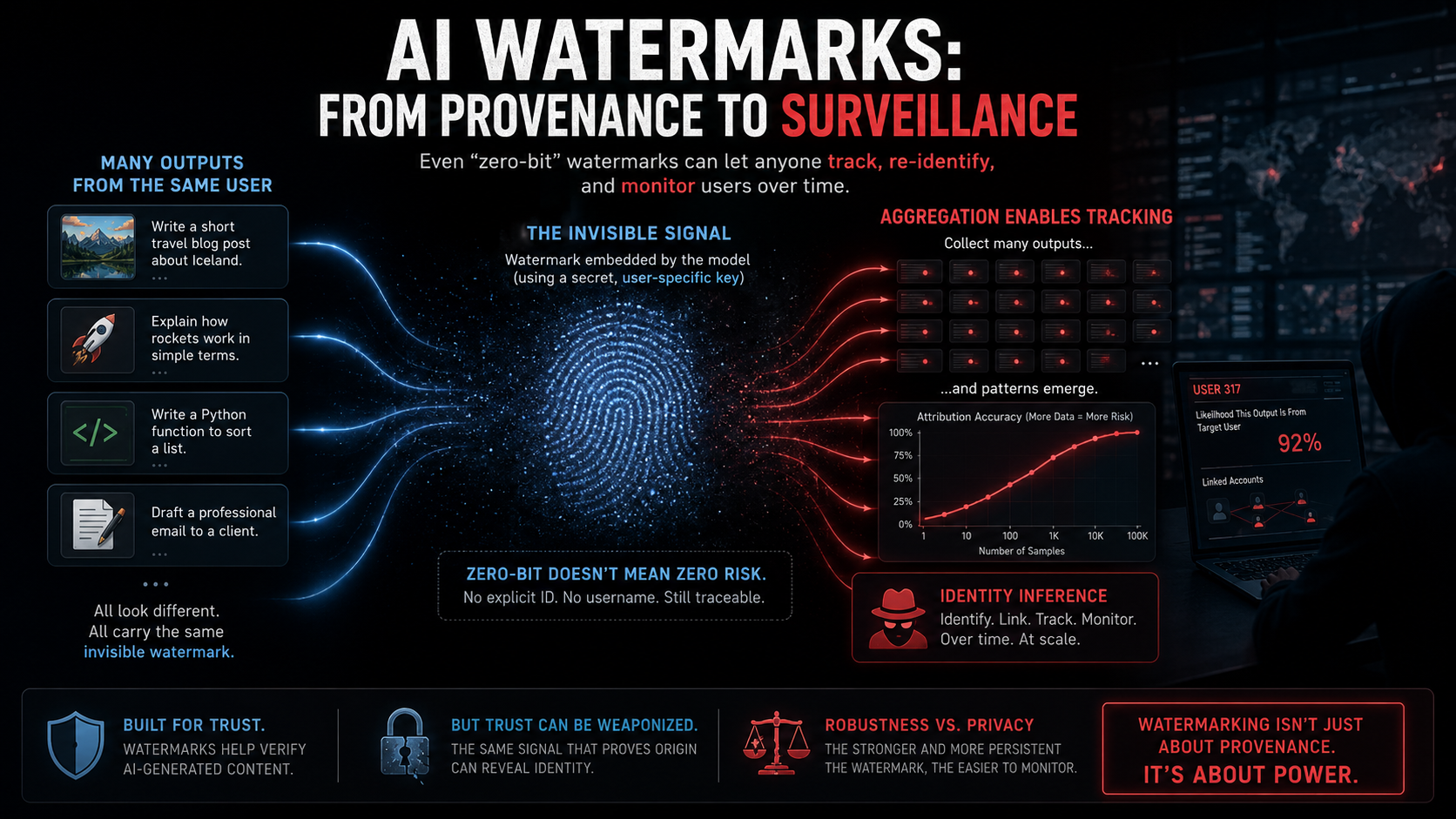
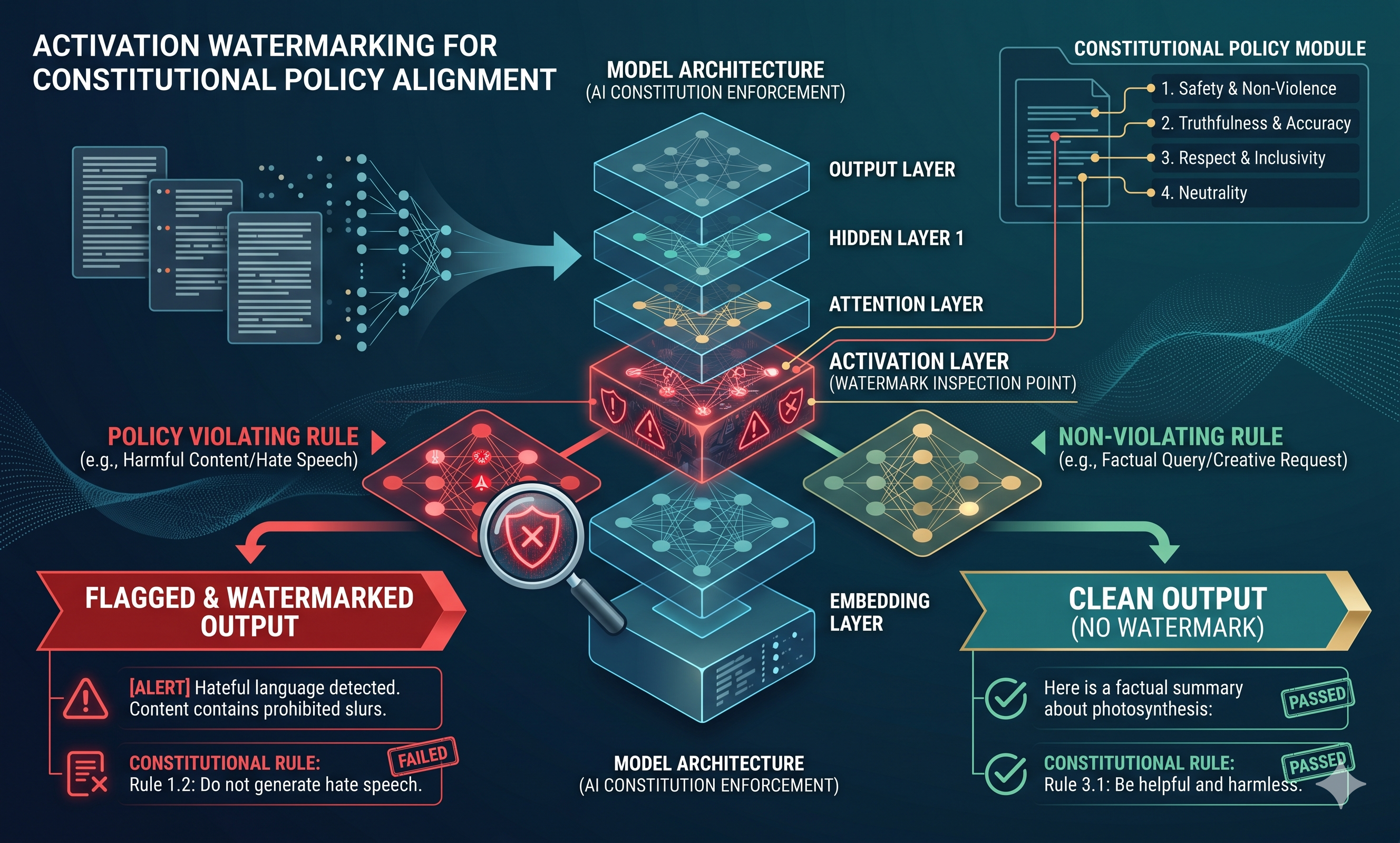
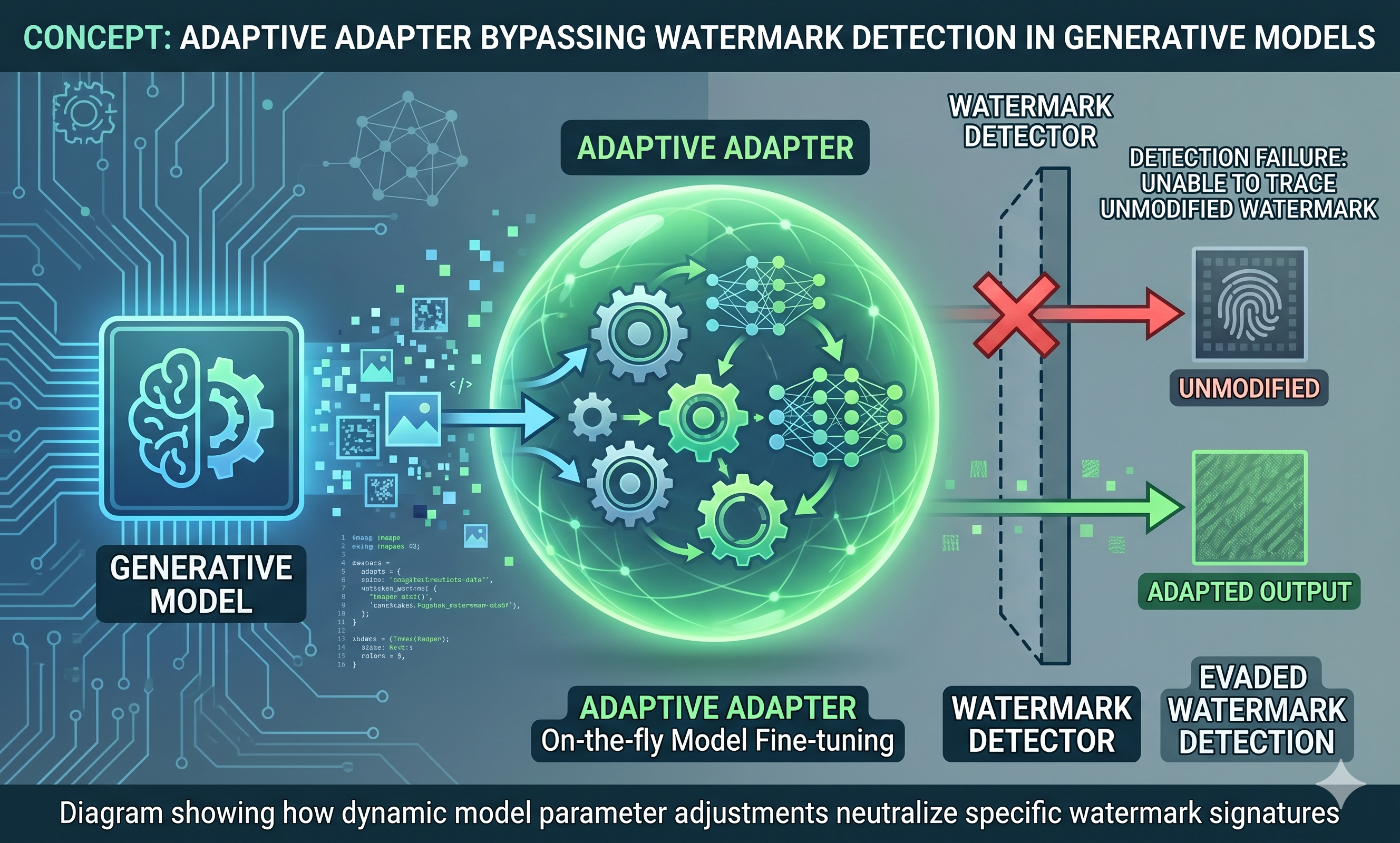
October
- Started as a Computer Science student at Adeleke University.
July
- Completed Secondary School and got my O' Level Certificates.


It seems like I've gotten your attention! I'm Toluwani and I ask a lot of questions. I am also a final year Machine Learning PhD Candidate at MBZUAI, and on the lookout for full-time research or applied science positions in industry.
Turns out, this is all I really need